결정트리란?
결정 트리 모델은 데이터의 특성들을 기준으로 샘플을 분류해 나가는데 그 모양이 나무를 닮아 결정 트리라고 불리운다.
결정트리의 각 노드는 " 뿌리(루트 노드), 규칙 노드(중간), 리프 노드(말단) " 로 나뉘며
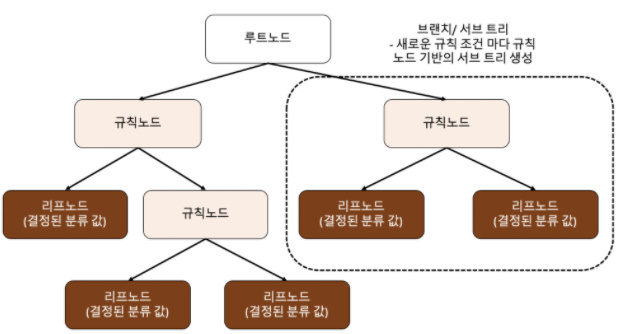
- 어떤 기준으로 규칙(어떻게 데이터를 분할해야 할지)을 만들어야 가장 효율적인 분류가 될 것인지가
알고리즘의 성능을 좌우한다. - 결정트리는 분류와 회귀문제에 모두 적용이 가능하며 새로운 데이터가 특정 말단 노드의 빈도가 가장
높은 범주로 데이터를 분류한다. - 규칙(데이터의 분류)가 많아 질수록 예측을 위한 학습이 잘 된다라고 말할 수 있지만 반대로 동시에 복잡하다는 의미를
가지며이는 과적합의 문제가 발생할 수 있다.
좋은 결정트리 학습 알고리즘이란?
앞서 말했지만 결정트리를 만든다는 것은 노드(데이터)를 어떻게 분할하는가에 관한 문제이다.
노드를 분할하는 방법에 따라 다양한 다른 모양의 트리구조가 만들어지는데
이때 결정트리의 비용함수를 정의하고 균일하게(데이터를 분류시 최대한 많은 데이터가 포함되어야 함)
나누는 것이 좋은 트리모델 알고리즘이다.
균일도를 측정하기 위해 트리학습에 자주 쓰이는 방법은 엔트로피를 이용한 정보이득 지수와 지니계수가 있다.
데이터 셋의 균일도는 데이터를 구분하는 과정에 있어 필요한 정보의 양에 영향을 미친다.
데이터 셋의 혼잡도가 높고(데이터가 많이 섞여있다는 의미) 균일도가 낮은 데이터의 경우 같은 조건에서 데이터를 판단하는데
많은 정보가 필요하고
정보이득은 엔트로피라는 개념을 기반으로 하는데,
지니계수(지니 불순도)는 계수가 낮을 수록 데이터의 균일도가 높다 의미,지니계수가 높다면 균일도가 낮음을 의미힌다.
불순도(Impurity) 알고리즘:
불순도라는 개념은 여러 범주들이 섞여 있는 정도를 의미한다.
결정트리를 만들어나갈 때 클래스(동일한 객체들끼리 모은 것)를 명확하게 구분해줄 수 있는
분류 기준을 찾는 것이 필요한데 불순도 알고리즘을 이용한다면 현재 집단에서 다른 객체들이 얼마나 섞여있는지를 파악할 수 있으며
불순도가 낮은 쪽으로 가지를 형성할 수 있도록 도와준다.
예를들어 데이터 클래스 비율이 50:50이라고 하면 불순도가 상당이 높다라고 말하며
90:10 비율이라고 하면 불순도가 낮다고 얘기 할 수 있다.
즉 지니계수가 높다는 것은 불순도가 높다는 의미이고 이는 균일도가 낮다는 의미이다.
균일도가 낮다는 의미는 데이터가 덜 섞여있다는 것이며
특성 중요도
우리가 사용하는 특성이 얼마나 일찍, 자주 사용되는지 지니계수를 계산
파이프라인
결측치 처리 - > 스케일링 -> 인코딩 -> X_train_encoded -> 모델
-> 가독성 향상
-> 코드 간결
-> 휴먼 에러 감소
파이프라인을 이해하고 활용하자
결정트리
선형회귀 - 거리를 계산하는 것
트리모델은 선형회귀와는 완전 다르다.
if~ then ~ else -> 규칙(Rule)을 발견
어떻게 나눌 것인가?? -> 기준(결정트리의 비용함수)
엔트로피,지니불순도
불순도??? 여러 범주가 섞여 있는 정도를 말한다.
결정트리에서는 standardscaler는 중요하지 않기에 사용하지 않는다.
특성중요도
선형회귀: 회귀계수로 파악이 가능 했음
특성중요도 얼마나 먼저, 자주 사용됬는지에 따라 중요도가 높게 나온다.
결정트리모델은 선형모델과 단리 비선형, 비단조, 특성상호작용 특징을 가지고 있는 데이터 분석에 용이하다.
https://velog.io/@ljs7463/%EA%B2%B0%EC%A0%95%ED%8A%B8%EB%A6%ACDecision-Tree%EB%AA%A8%EB%8D%B8Model
'AI > 머신러닝' 카테고리의 다른 글
| Confusion Matrix란? (0) | 2022.03.04 |
|---|---|
| 랜덤 포레스트(Random Forests), 앙상블 기법 (0) | 2022.03.03 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2022.02.25 |
| 머신러닝에서 훈련/검증/테스트 세트로 나누는 이유 (0) | 2022.02.25 |
| One-hot encoding과 Ridge Regression (0) | 2022.02.24 |




댓글